事实上,采用 MariaDB 作为数据库,一般是两种情况:
1 是觉得 MySQL 被 Oracle 收购之后,继续使用 MySQL 心里不踏实(license 和发展前景等)。
2 是想另外找一个生命力比较旺盛、小区比较丰富的关系型数据库。
所以一般默认的 InnoDB 和 Aria 就足够满足大部分的需求了。
不过连接处理到其它数据库,或者加载到 MariaDB 中的需求还是比较多的。例如将一份 json 文件 存在大量需要加载到 MariaDB 数据库中的数据时,这个时候就比较需要使用 CONNECT 引擎了。
注意:CONNECT 是连接到远程数据,并没有转存到 MariaDB 中。所以远程数据源的异动,MariaDB 处理查德德询得到的也是异动后的数据。
在官网(https://mariadb.com/kb/en/introduction-to-the-connect-engine/)可以看到 CONNECT 更多特性。
CONNECT 的安装与卸载
Connect Storage Engine 并未封装于 MariaDB Package 内,需要透过 Repository 安装:
sudo apt install mariadb-plugin-connect会同时安装依赖库 libodbc1
然后再安装插件(我测试时已有默认安装上并启用,如果没有默热安装启用,执行此句)
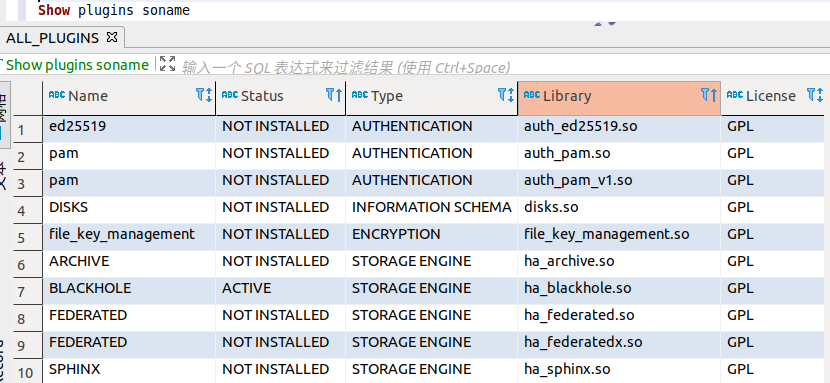
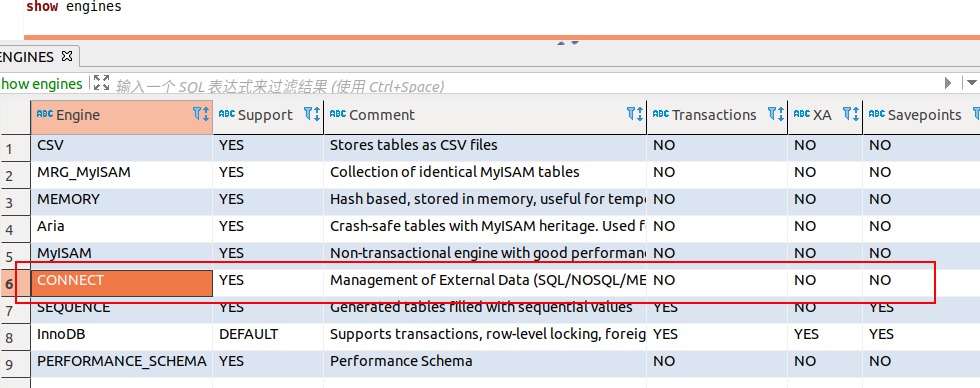
install soname 'ha_connect'此次,查看引擎可以看到新装的 CONNECT:
卸载,执行UNINSTALL SONAME 'ha_connect';即可。
使用 CONNECT 连接处理 json 文件
有两点要做:1 是指定表的类型,2 是指定要连接的文件(远程表)的类型和文件名。
前者是创建表时要指定engine=CONNECT,后者是要针对需要访问的不同类型的文件,指定 table_type 参数为指定类型。
目前,table_type 的类型有很多种,除了常见的 json、csv、xml,还有例如
BIN, DBF, DIR, DOS, FIX, ZIP, JDBC, ODBC, MONGO, MYSQL, WMI, MAC 等。
以 json 为例
1、准备一份JsonDemo.json文件如下(官网示例)
[
{
"ISBN": "9782212090819",
"LANG": "fr",
"SUBJECT": "applications",
"AUTHOR": [
{
"FIRSTNAME": "Jean-Christophe",
"LASTNAME": "Bernadac"
},
{
"FIRSTNAME": "François",
"LASTNAME": "Knab"
}
],
"TITLE": "Construire une application XML",
"PUBLISHER": {
"NAME": "Eyrolles",
"PLACE": "Paris"
},
"DATEPUB": 1999
},
{
"ISBN": "9782840825685",
"LANG": "fr",
"SUBJECT": "applications",
"AUTHOR": [
{
"FIRSTNAME": "William J.",
"LASTNAME": "Pardi"
}
],
"TITLE": "XML en Action",
"TRANSLATED": {
"PREFIX": "adapté de l'anglais par",
"TRANSLATOR": {
"FIRSTNAME": "James",
"LASTNAME": "Guerin"
}
},
"PUBLISHER": {
"NAME": "Microsoft Press",
"PLACE": "Paris"
},
"DATEPUB": 1999
}
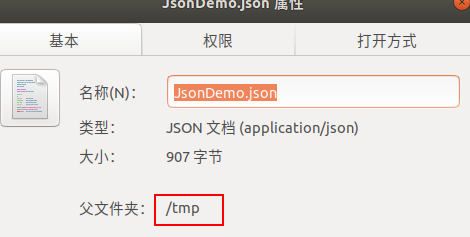
]2、放到一个 MariaDB 可以访问的路径
这一点很重要,否则可能报错:
SQL 错误 [1296] [HY000]: (conn=65) Got error 174 'Open(map) error 13 on //JsonDemo.json' from CONNECT 例如本例放到了/tmp 活页夹下
3、MariaDB 命令窗口执行测试
语句及说明如下:
-- 创建一个数据库
CREATE DATABASE test200222;
-- 在数据库中新建一张表,并制定engine为CONNECT,
-- table_type为JSON,File_name为json文件存放位置
DROP table if exists test200222.jsample;
create table test200222.jsample (
ISBN char(15),
LANG char(2),
SUBJECT char(32),
AUTHOR char(128),
TITLE char(32),
TRANSLATED char(80),
PUBLISHER char(20),
DATEPUB int(4)
)
engine=CONNECT table_type=JSON
File_name='/tmp/JsonDemo.json';
-- 条件查询,查看是否有数据
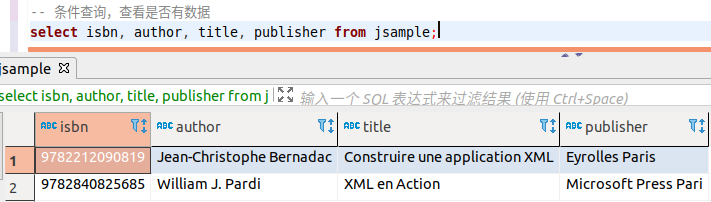
select isbn, author, title, publisher from test200222.jsample;查询结果应当如下
问题说明:
从查询的结果可以看出,在 JSON 中,isbn 为 9782212*的书的作者,是两个人,读入的存储结果只有一个人。
这是因为,默认情况下,遇到数组时,它只会读取数组的第一个值。
事实上,json 文件大部分情况下,都不可能只有一层,值是数据应该常见。
因此 CONNECT 启用一个特殊的字段field_format选项 Jpath,用来描述如何显示和处理数组。
新建 jsample2 表,指定 field_format 字段:
DROP table if exists test200222.jsample2;
create table test200222.jsample2 (
ISBN char(15),
Language char(2) field_format='LANG',
Subject char(32) field_format='SUBJECT',
Author char(128) field_format='AUTHOR.[" and "]',
Title char(32) field_format='TITLE',
Translation char(32) field_format='TRANSLATOR.PREFIX',
Translator char(80) field_format='TRANSLATOR',
Publisher char(20) field_format='PUBLISHER.NAME',
Location char(16) field_format='PUBLISHER.PLACE',
Year int(4) field_format='DATEPUB'
)
engine=CONNECT table_type=JSON
File_name='/tmp/JsonDemo.json';注意,在 Connect 1.5,json 对象取值用的是”:”,Connect 1.6 使用”.”。
同样查询一次:
select isbn, author, title, publisher from jsample2;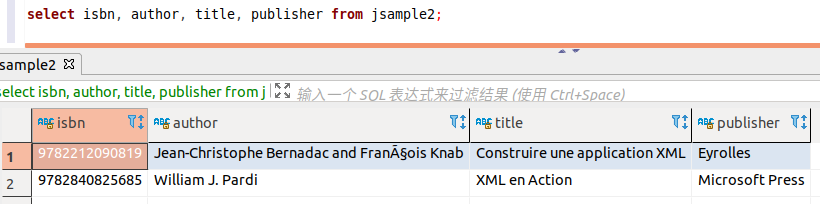
当然,除了把数组的值合并到一起,还可以根据数组的值将数据拆成 2 条。
新建 jsample3 表如下:
DROP table if exists test200222.jsample3;
create table test200222.jsample3 (
ISBN char(15),
Title char(32) field_format='TITLE',
AuthorFN char(128) field_format='AUTHOR.[*].FIRSTNAME',
AuthorLN char(128) field_format='AUTHOR.[*].LASTNAME',
Year int(4) field_format='DATEPUB'
)
engine=CONNECT table_type=JSON
File_name='/tmp/JsonDemo.json';注意,在 Connect 1.5,1.6,json 对象拓展符用的是”X”,Connect 1.06.006:使用”*“。
查看结果:
SELECT * FROM test200222.jsample3;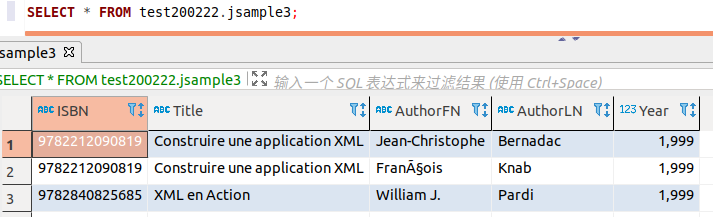
从上可以简单窥见,’:’已被’.’取代,’[*]’已用来表示扩展,而’[X]’表示乘法。
更多 Jpath 数组规范可见下表:
Jpath 规范
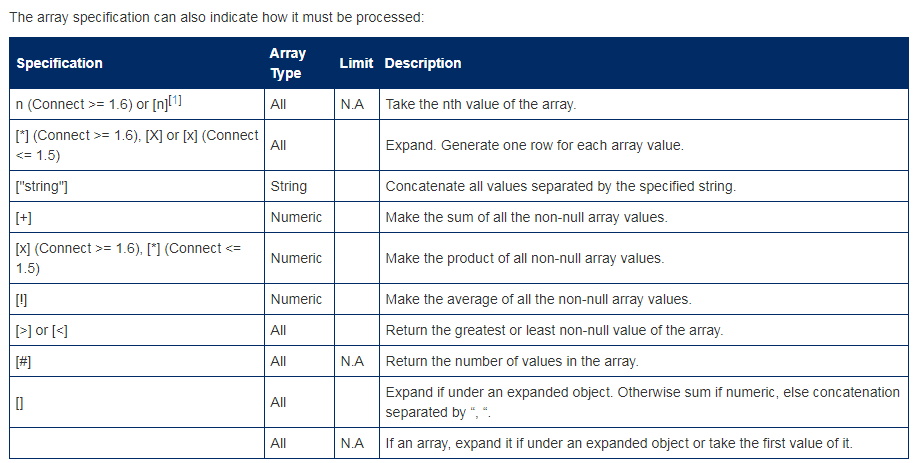
更多 CONNECT 对 json 文件的处理,可参看官网:https://mariadb.com/kb/en/connect-json-table-type/
此外,除了对 JSON 文件,还有对其它常见文件的处理例如 csv、xml,都可以到官网https://mariadb.com/kb/en/connect-table-types/查看对应的table_type了解实践。