在使用 MariaDB 之后,肯定也会希望它能够按照一定设定、规则等进行合理的性能优化,提高效能等。此篇将从常见的一些 mariadb-server 的设定上,简单介绍调整 MariaDB 期望能以最佳性能进行运行。
主要简介以下几种:
- 1、启用服务器内置特定最佳化参数设定(optimizer_switch)
- 2、线程池(thread pool)
- 3、查询缓存(query cache)
- 4、MyISAM 键缓存(Key Cache)
- 5、InnoDB 缓冲池(Buffer Pool)
- 6 优化表 (OPTIMIZE TABLE)
在此之前,需要记住 mariadb server 常用的查看状态的几个命令:show status;、show variables;、show engines;,当然都可以附加like关键词筛选。
1、启用服务器内置特定最佳化参数设定
使用 switch 方式开关 MariaDB 特定的最佳化机制,系统变量:@@optimizer_switch。
这一个服务器变量,可以用来启用/禁用特定的优化。
可以使用SELECT @@optimizer_switch;来查看 mariadb-server 默认支持哪一些参数的优化(为了一眼看到全貌,此处就用 MariaDB 的命令窗口看):
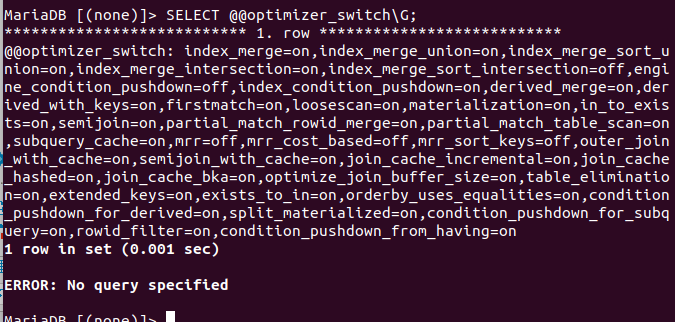
可见,很多 server 的配置的优化,都是有开启的。后续在使用时,可以根据使用到的功能,启用这些设定。
修改方式一如既往:
SET [GLOBAL|SESSION] optimizer_switch='cmd[,cmd]...';例如set optimizer_switch="engine_condition_pushdown=on";
当然,重启就失效了,修改配置文件操作,在配置文件[mysqld]下新增:
[mysqld]
optimizer_switch="engine_condition_pushdown=on"更多最佳化开关的信息,可以查看官网: https://mariadb.com/kb/en/optimizer-switch/ 了解。
2、线程池(thread pool)
简介
- MariaDB 5.5 引入
- 传统 MySQL 采用 One Thread Per Client 设计
- 改用 dynamic/adaptive Pool 方式提供所有 Clients
- 依据状况自动 grows/shrink Pool size
- 依据操作系统自动调整最佳设定
- 降低内存使用量 , 降低 context switch 造成的问题
- 注意:建立 Threads 需要时间 !!!
- Windows 版本默认值: ThreadPool (排队等候 Threads 使用权)
- Linux 版本预设: One thread Per Client (所有 Threads 都会轮流)
使用时机:
- 适合 Short-queries , CPU-Bound 类型的应用
- 例如 Web Site 或是 OLTP 类型的应用
- IoT 类型应用: 短查询, 短 I/O ,密集 CPU 使用
不适合时机:
- 高负载/瞬间爆量/不容许延迟
- 长时间无任务, 瞬间爆量然后又消失一段时间的查询
- |— 回收线程, —->新增线程 —-> 回收线程
- 此类任务,使用 一核心 一线程策略取代
- 大量 同时发生/长时间执行/长时间占用 的查询应用
- 使用少量线程负担所有联机 需要 queue—> scheduler
- 低延迟要求的查询应用
使用配置
linux 启用线程池
在配置文件的[mariadb]参数下:
[mariadb]
thread_handling=pool-of-threadswindows 下启用线程池
在配置文件的[mariadb]参数下:
[mariadb]
thread_handling=one-thread-per-connection3、查询缓存(query cache)
查询缓存存储 SELECT 查询的结果,以便将来以后收到相同的查询时,可以快速返回结果。
这在高读、低写环境(例如大多数网站)中非常有用。在多核计算器上具有高吞吐量的环境中,它无法很好地扩展。
可以查看对应的参数设定:show variables like '%query_cache%';和show status like 'Qcache%'; ,并修改为符合自身设备和需求需要的值。
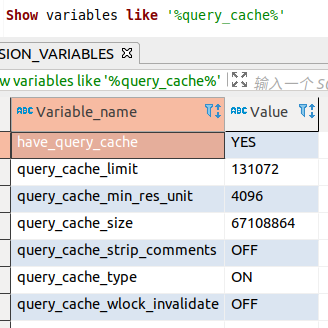
说明:此种类似的系统变量,一般在配置文件的[mysqld]参数下寻找来修改或添加。若不是,查看官网指定参数是否是在其它变量下。
如果某些查询,要求不允许使用查询缓存里面的值,则可以在 select 加入 SQL_NO_CACHE 去说明。同样,指定要从查询缓存中查询,也可以在 select 后指定 SQL_CACHE。
示例:
Select SQL_NO_CACHE … from table …或者
Select SQL_CACHE … from table …注意:这些参数的设定还是有一些限制的,例如因为查询缓存大小以 1024 字节做分配,因此应该将 query_cache_size 设置未 1024 的倍数。
例如,设置 query_cache_size 大小为 40000 就会出现警告:
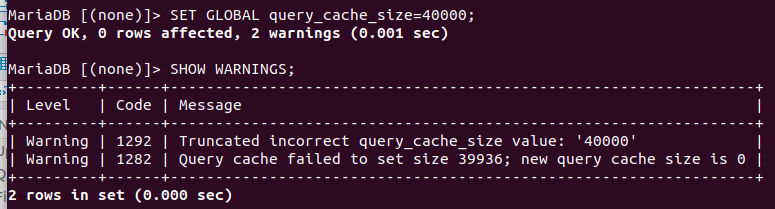
查询结果存储使用的最小块大小是 query_cache_min_res_unit。
更多信息可以访问官网https://mariadb.com/kb/en/query-cache/#limiting-the-size-of-the-query-cache了解。
子查询缓存(SubQuery Cache)
MariaDB 独有的快取设计 ,在 MariaDB 5.3.2 预设启用。透过绑定主要查询与子查询结果,避免重复执行子查询。
设定方式:
透过 optimizer_switch 设定
SET optimizer_switch="subquery_cache=on"4、MyISAM 键缓存(Key Cache)
在 MariaDB 使用 MyISAM 引擎时,可以设定 key_cache_segments 进行一些优化。
分段密钥缓存(segmented key cache)是常规 MyISAM 密钥缓存(key caches)的结构的集合,称为密钥缓存段(key cache segments)。分段密钥缓存减轻了简单密钥缓存的主要问题之一:密钥缓存锁(mutex)的线程争用。对于常规的键高速缓存,键高速缓存接口功能的每次调用都必须获得此锁。因此,即使线程已获取文件的共享锁并且要从中读取的页面位于键高速缓存缓冲区中,线程也争夺该锁。
使用分段键高速缓存时,仅需要一页的任何键高速缓存接口功能都必须仅为分配该页面的段获取键高速缓存锁。这使线程不必竞争同一密钥缓存锁的机会就更好了。
(更多内容查看官网https://mariadb.com/kb/en/segmented-key-cache/)
在并行(concurrent)不成熟的年代使用 SingleThread Access 特性,造成大量存取产生 Mutex Lock & wait 问题。
将 key cache 切成多段可允许同时多个 MyISAM Threads 同时存取,减少锁和等待。
配置:
设定全局变量
Set Global key_cache_segments=n注意,n 只能时 0~64,大于 64 会被截断成 64 并报警告。
或在配置文件修改,找到[mysqld]参数下添加:
[mysqld]
key_cache_segments = 645、InnoDB 缓冲池(Buffer Pool)
XtraDB / InnoDB 的缓冲池是用于优化 MariaDB 的一个关键组成部分。它存储数据和索引,通常希望它尽可能大,以便将尽可能多的数据和索引保留在内存中,从而减少磁盘 IO 成为主要瓶颈。
一般设定 70% ~ 80% 的主机内存用于存放 XtraDB/InnoDB 的数据与索引,将常用的 data-blocks & index-blocks 暂存在内存中。
缓冲池如何工作
缓冲池尝试将经常使用的块保留在缓冲区中,因此实际上起着两个子列表的作用,一个是最近使用信息的新子列表(New sublist),另一个是旧信息的旧子列表(Old sublist)。默认情况下,列表的 37%保留用于旧子列表。
当访问未出现在列表中的新信息时,它将被放置在旧子列表的顶部,旧子列表中最旧的项目将被删除,其它所有内容都将返回列表中的一个位置。
当访问的信息出现在旧子列表中时,它将被移到新列表的顶部,并且上方的所有内容将移回一个位置。
InnoDB 的 Buffer 管理
一般 select 的执行:
Select SQL—> InnoDB 引擎–> Cache 寻找 –>无 —>执行查询–>结果–>存入 InnoDB Buffer ( New | Old ? ) –> 存入 old-list buffer
后续的查询:
SQL —> InnoDB 引擎 —> cache 中发现(old-list) –> 将该笔快取资料从 old-list 放入 new-list 中的第一顺位 –> 被挤出去的数据 存入 old-list –> Old-list 最后一笔被踢出 buffer (从 cache 中移除)
InnoDB 4 个重要的缓冲池服务器系统变量:
innodb_buffer_pool_size (innodb 缓存池大小)
设定 70~80% Memory Size ( + 10% 的控制暂存区使用 )。过大容易造成 OS Swapping 或是过长的初始化时程。
例如:启动后 8G ram 被吃掉 6.4G 用于快取, 当 server 需要执行其它应用程序时,需要 2G ram , 此时将导致 OS 发生 ram-disk swapping。
在 MariaDB 10.2.2 之后,可以动态调整 InnoDB Buffer size。
调整缓冲池大小的过程由 innodb_buffer_pool_chunk_size 变量的大小确定。
调整大小操作将一直等到所有活动事务和操作完成,并且需要访问缓冲池的新事务和操作必须等到调整大小完成为止(尽管减小大小时,在对页面进行碎片整理和撤回时允许访问)。
如果在缓冲池调整大小开始之后启动嵌套事务,则该事务可能会失败。
新的缓冲池大小必须是 innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances 的倍数。如果尝试设置其它数字,则该值将自动调整为至少为尝试的大小的倍数。请注意,调整 innodb_buffer_pool_chunk_size 设置可能会导致缓冲池大小发生变化。
为了避免性能问题,由 innodb_buffer_pool_size / innodb_buffer_pool_chunk_size 计算的块数不应超过 1000。
innodb_buffer_pool_instances (inondb 缓存池示例数量)
- innodb_buffer_pool_size 超过 1G 时, 透过设定的 pool instances 将其切割成多个,instances 提供同时 (concurrent) 存取, 增进效能。
- MariaDB 10 预设为 8 (请参考 CPU Core 数,勿无谓增加)。
- 每个 instance 负责管理各自所保存的 buffer 数据。
例如:若 pool size 设定为 4G , instances 设定为 4,则产生四组 1G size 的 instances 保存 buffer 数据。
innodb_old_blocks_pct
可以通过更改 innodb_old_blocks_pct 的值来调整为旧子列表保留的默认 37%的值。它可以接受 5%至 95%之间的任何值。
innodb_old_block_time
指定之前的块可以从旧子列表被移动到新子列表的延迟。
MariaDB 5.5 时默认值为 0,表示没有延迟,而自 MariaDB 10.0 起已设置为默认值 1000ms。
在更改这两个值(innodb_old_blocks_pct 和 innodb_old_blocks_time)的默认值之前,请确保了解其影响以及系统当前使用缓冲区的方式。它们存在的主要原因是为了减少全表扫描的影响,这种情况通常很少见,但很大,而且以前可以从缓冲区中清除所有内容。在快速连续执行全表扫描的情况下,设置非零延迟可能会有所帮助。
转储和还原缓冲池
自 MariaDB 10.0 起,可以转储并还原缓冲池。
服务器启动时,缓冲池为空。在开始访问数据时,缓冲池将慢慢填充。随着将访问更多数据,最常访问的数据将被放入缓冲池,并且旧数据可能会被驱逐。这意味着缓冲池真正有用之前需要一定的时间。该时间段称为预热。
从 MariaDB 10.0 开始,InnoDB 可以在服务器关闭之前转储缓冲池,并在再次启动时将其还原。如果使用此功能,则无需预热。 要分别在关闭时启用缓冲池转储和在启动时启用还原,可以将 innodb_buffer_pool_dump_at_shutdown 和 innodb_buffer_pool_load_at_startup 系统变量设置为 ON。
在服务器运行时,还可以随时转储 InnoDB 缓冲池,并且可以随时恢复上一次缓冲池转储。为此,可以将特殊的 innodb_buffer_pool_dump_now 和 innodb_buffer_pool_load_now 系统变量设置为 ON。选择后,它们的值始终为 OFF。
通过将 innodb_buffer_pool_load_abort 设置为 ON ,可以中止在启动时或在其它任何时间进行的缓冲池还原。
包含缓冲池转储的文件是通过 innodb_buffer_pool_filename 系统变量指定的。
转储和还原缓冲池这一段官网描述得非常清楚明了,我就不再加工说明了。
6 优化表 (OPTIMIZE TABLE)
优化表的功能有两个:对表进行碎片化处理(defragment tables),或者更新 InnoDB 全文索引(update the InnoDB fulltext index.)
语法:
OPTIMIZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE
tbl_name [, tbl_name] ...
[WAIT n | NOWAIT]碎片整理
OPTIMIZE TABLE 适用于 InnoDB(在 MariaDB 10.1.1 之前,仅当设置了 InnoDB_file_per_TABLE server 系统变量)、Aria、MyISAM 和 ARCHIVE 表时,如果删除了表的很大一部分,或者对具有可变长度行(具有 VARCHAR、VARBINARY、BLOB 或 TEXT 列的表)的表进行了许多更改,则应使用 OPTIMIZE TABLE。 已删除的行保留在链接列表中,后续插入操作将重用旧的行位置。
此语句要求表具有选择和插入权限。
默认情况下,OPTIMIZE TABLE 语句将写入二进制日志并进行复制。NO_WRITE_TO_BINLOG 关键字(LOCAL 是别名)将确保语句不会写入二进制日志。
分区表也支持优化表。您可以使用
ALTER TABLE优化分区以优化一个或多个分区。
可以使用优化表回收未使用的空间并对数据文件进行碎片整理。对于其它存储引擎,OPTIMIZE TABLE 默认情况下不执行任何操作,并返回以下消息:“表的存储引擎不支持 OPTIMIZE”。但是,如果服务器已使用–skip new 选项启动,那么 OPTIMIZE TABLE 将链接到 ALTER TABLE,并重新创建该表。此操作释放未使用的空间并更新索引统计信息。
自 MariaDB 5.3 以来,Aria 存储引擎支持此语句的进度报告。
如果 MyISAM 表是分段的,则除非在该表上执行优化表语句,否则不会执行并发插入,除非将 concurrent_insert server 系统变量设置为 ALWAYS。
更新 InnoDB 全文索引
当向 InnoDB 全文索引添加或删除行时,不会立即重新组织索引,因为这可能是一个代价高昂的操作。更改统计信息存储在单独的位置。只有在运行优化表语句时,全文索引才会完全重新组织。
默认情况下,优化表将对表进行碎片整理。为了使用它更新全文索引统计信息,innodb_optimize_fulltext_only 系统变量必须设置为 1。这是一个临时设置,应在重新组织全文索引后重置为 0。
由于全文重新组织可能需要很长时间,innodb_ft_num_word_optimize 变量将重新组织限制为多个单词(默认为 2000)。可以运行多个优化语句来完全重新组织索引。
值得一提:碎片化整理和更新全文索引的时机,在大量数据得删除或大量 可变长度行字段异动之后
一个非常好的例子,MariaDB 的数据库文件.ibd 文件,在大量删除之后,体积不会变小,执行OPTIMIZE TABLE (MyISAM 优化 table)或ALTER TABLE (‘InnoDB’优化 table)之后,体积就会肉眼可见的变小。
(.ibd 文件默认位置/var/lib/mysql/
更多性能优化相关知识,可到官网https://mariadb.com/kb/en/optimization-and-tuning/ 学习了解。