存储引擎简述
- 简单说来,存储引擎是数据库管理系统用来从数据库创建、读取、更新数据的软件模块。
- 负责提供数据实体储存的算法
- 提供数据文件与索引档案的管理
- MariaDB 采用 Plugin 方式动态加载/卸载 引擎模块
- 可透过外部安装的方式添加新的 Storage Engine
查询指令:
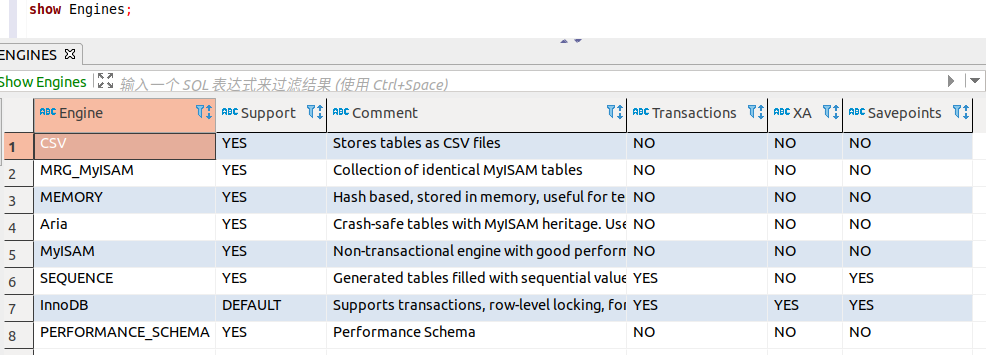
查看所有的已启用的存储引擎:show engines;
查询预设引擎:select @@global.storage_engine;
简单介绍几个 MariaDB 的存储引擎
1、InnoDB/XtraDB
- XtraDB 属于 InnoDB 分支( Percona 负责维护),针对“效能与监控”进行强化,兼容 InnoDB 引擎。MariaDB 10.1 采用 (MariaDB 10.1),但在 MariaDB 10.2 回归 MySQL InnoDB 。
- 支持 Trasaction/Savepoints 以及 XA Transaction。
- 现代 IoT/BigData: 大量数据与快速写入上出现瓶颈。
2、MyISAM
- MySQL/MariaDB 最早的预设引擎
- 轻量化设计不支持交易(Trasaction)处理
- 适合 read-heavy workload
- 无事务无日志,因此档案容易因其它因素而损毁
- 过渡时期的 Big Data 处理方式
3、Aria
- 原名 Maria,MariaDB 5.1 导入
- MariaDB 10.4 后 System Tables 全面改用 Aria
- Crash Safe ,采用 log 进行 数据还原(data recovery)
- 采用 page 提供更快速 不易产生 Fragment 的储存算法
- 建议改用 Aria 取代 MyISAM
4、TokuDB
- 由 Tokutek 负责开发,MariaDB 5.5 纳入此引擎模块
- 支持数据压缩(data compression)
- 支持大型数据处理,速度快于 InnoDB
- 适合高效能与写密集型(write-intensive) 需求的应用环境
5、MyRocks
- Facebook 所发展的数据储存技术
- MyRocks 是将 RocksDB 数据库添加到 MariaDB 的存储引擎。RocksDB 是一个 LSM 数据库,具有很大的压缩率,已针对闪存进行了优化
- 提供高效能的压缩与 I/O 效能
- 降低数据空间需求
6、Connect
- MariaDB 10.0 导入,透过 Connect Plugin 让 MariaDB 连接不同的数据来源, 提供外部数据(MED: Management External Data)给 MariaDB Client
- 标准规范: SQL/MED
- 提供多种类型的数据连接服务
- 定义 Wrapper Table 提供 Client 存取
按用途选择存储引擎
MariaDB 有几十种存储引擎,但并不一定都是最佳。官网有简单针对各种用于,建议使用不同的引擎。大概如下:
一般用途:
- 在 MariaDB 10.1 之前,XtraDB 是大多数情况下的最佳选择。它是 InnoDB 增强性能的分支,并且是 MariaDB 10.1 之前的默认引擎。
- InnoDB 是一个很好的常规事务存储引擎。它是 MariaDB 10.2(以及 MySQL)的默认存储引擎。对于早期版本,XtraDB 是 InnoDB 的性能增强分支,通常是首选。
- Aria 是 MariaDB 基于 MyISAM 上的更加现代改进,占用空间小,并且让系统之间相互复制很简单。
- MyISAM 占用空间小,也可轻松在系统之间进行复制。MyISAM 是 MySQL 最古老的存储引擎。但是除了解决遗留问题用途,通常没有其它理由使用它。Aria 是 MariaDB 的更现代改进。
缩放,分区(Scaling, Partitioning):
如果想要拆分数据库并加载在几个服务器上,或者优化缩放,建议使用 Galera(一个同步多主集群)。
- TokuDB 是一个事务性存储引擎,它针对不适合内存的工作负载进行了优化,并提供了良好的压缩比。
- Spider 使用分区(partitioning)通过多个服务器提供数据分片(data sharding)。
- ColumnStore 采用大规模并行分布式数据体系结构,专为大数据扩展而设计,可处理 PB 级别的数据。
- MERGE 存储引擎是一个相同 MyISAM 表的集合,所有表具有相同的列和索引信息。
压缩/归档(Compression / Archive)
- MyRocks 相比与 InnoDB,可以实现更大的压缩,更小的写入放大率(write amplification),从而可以更好地承受闪存存储并提高整体吞吐量。
- TokuDB 是一个事务性存储引擎,它针对不适合内存的工作负载进行了优化,并提供了良好的压缩比。
- Archive 存储引擎,勿庸置疑,最适合用于归档。
连接到其它数据源
如果要使用的数据没有存放到 MariaDB 数据库,但可以通过以下的数据引擎去连接访问。
- CONNECT 允许访问不同类型的文本文件和远程资源,就像它们是常规的 MariaDB 表一样。
- CSV 存储引擎可以读取并附加到以 CSV(逗号分隔值)格式存储的文件。然而,自从 MariaDB 10.0 以来,CONNECT 是一个更好的选择,并且能够更灵活地读写这样的文件。
- FederatedX 使用 libmysql 与远程 RDBMS 数据源沟通。目前,由于 FederatedX 只使用 libmysql,它只能与另一个 MySQL RDBMS 通信。
- CassandraSE 是一个允许访问旧版本的 Apache Cassandra NoSQL DBMS 的存储引擎。不过它是相对实验性的,并且不再被积极开发。
搜索优化
- SphinxSE 用作在远程 Sphinx 数据库服务器上运行语句的代理(主要用于高级全文搜索)。
- Mroonga 使用列存储提供快速的 CJK 就绪全文搜索。
缓存,只读
- MEMORY 不会在磁盘上写数据(崩溃时所有行都会丢失),并且最适合用于其它表中数据的只读缓存或临时工作区。借助默认的 XtraDB 和其它具有良好缓存的存储引擎,与过去相比,对该引擎的需求减少了。
其它专用引擎
- S3 存储引擎是一个只读存储引擎,它将数据存储在 amazons3 中。
- Sequence 允许使用给定的起始值、结束值和增量创建数字(正整数)的升序或降序序列,并在需要时自动创建虚拟的临时表。
- BLACKHOLE 存储引擎接受数据,但不存储数据,并始终返回空结果。这在复制环境中非常有用,例如,如果您希望在从机上运行复杂的筛选规则,而不会在主机上产生任何开销。
- OQGRAPH 允许处理层次结构(树结构)和复杂图(在多个方向上有多个连接的节点)。
总结:
关于 MariaDB 存储引擎的一般性常规选择(先不考虑拓展和集群),其实大体看来只有以下几个
- 一般使用:InnoDB
- 快速存取,不使用事务:Aria
- 高压缩和吞吐,需要降低数据空间占比:MyRocks 或 TokuDB
- 归档专用:Archive
- 连接到其它文本或远程数据源:CONNECT
更多 MariaDB 的存储引擎详细,可参看官网https://mariadb.com/kb/en/storage-engines/