新的问题:
若数据量即使使用 Partition,都不是单一台主机有办法处理;
存放要分散,但存取要集中。
这个时候,就可以考虑 Spider 存储引擎。
事实上,对于数据驱动的功能,都可能面临类似的问题,数据库日益膨大,单表、单数据库、单机器已经不能存储和处理数据了。 所以会有上述说明的分片设计。
针对不同程度的数据,会选择到不同的具体分片实现,这也是上述说明的各种单表的分区作业。
不过基于有些引擎的限制或者功能不够强大,可能在数据库分片上无法实现跨设备的作业。
但是 Spider 引擎可能提供了一个比较好的解决方案。
Spider 是什么?
Spider 是 MariaDB 内置的一个可插拔用于 MariaDB/MySQL 数据库分片的存储引擎,充当应用服务器和远程后端 DB 之间的代理(中间件),它可以轻松实现 MariaDB/MySQL 的横向和纵向扩展,突破单台 MariaDB/MySQL 的限制,支持范围分区、列表分区、哈希分区,支持 XA 分布式事务,支持跨库 join。完成数据库跨越多组实例(instances)。
使用 Spider 存储引擎创建表后,该表将链接到远程服务器上的表。远程表可以是任何存储引擎。通过建立从本地 MariaDB 服务器到远程 MariaDB 服务器的连接,可以具体实现表链接。该链接对于属于同一事务的所有表共享。
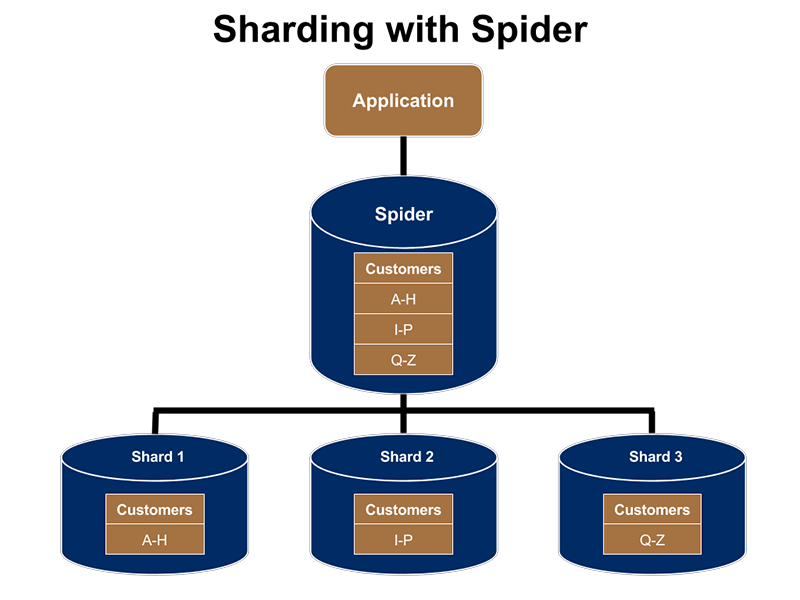
简单说起来:
Spider 首先提供的是从另一个 MariaDB 服务器访问一个 MariaDB 服务器(也可以是其它类型数据库服务器)上的表的方法。
保存实际表数据的 MariaDB 服务器上根本没有任何特定的 Spider 代码,它是一个普通的 MariaDB 服务器。MariaDB 服务器被配置为访问该数据,然后使用 Spider 存储引擎使用通常的 MariaDB 协议访问另一台服务器上的数据。

图源 mariadb 博客(https://mariadb.com/resources/blog/uses-for-mariadb-and-the-spider-storage-engine/)
可以看到,Spider 只在引用节点上处于活动状态,目标节点不需要安装 Spider。创建“spider 表”意味着我们定义一个表,该表包含目标表中相同列或列的子集,并引用目标服务器。
还要注意,“spider 节点”上没有这些表的数据,也没有重复的数据,所有数据都驻留在目标节点上。
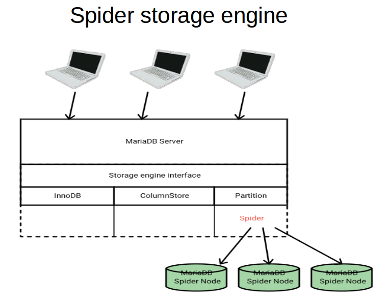
Spider 存储引起核心概念
这是几乎每一篇介绍 Spider 的文章都会提到的东西。
典型的 Spider 部署有一个无共享的集群架构(shared-nothing clustered architecture)。这个系统可以使用任何满足对硬件或软件有最低的特定要求的硬件。它由一组运行有一个或多个称为节点(node)的 MariaDB 进程的主机(computers)组成。
存储数据的节点将被设计为后端节点(Backend Nodes),可以是使用后端中可用的任何存储引擎的任何 MariaDB、MySQL、Oracle 服务器实例。
Spider 代理节点(Spider Proxy Nodes)是至少运行 MariaDB 10 版本上,用于向后端节点声明每个表的附件(attachment)。此外,还可以设置 Spider 代理节点,以便将表拆分并镜像到多个后端节点。
Spider 常见用例:
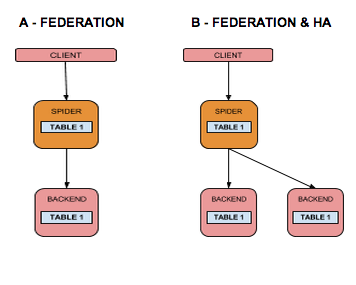
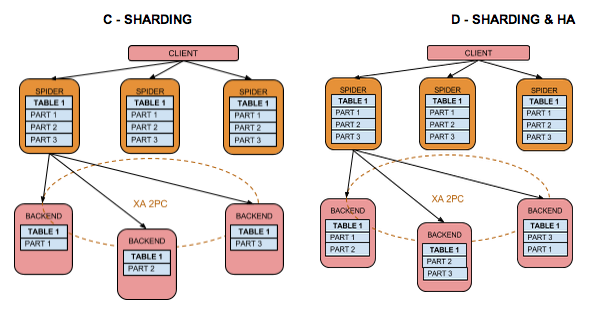
图源官网(https://mariadb.com/kb/en/spider-storage-engine-core-concepts/)
此外 Spider 引擎的底层架构和优化设计还是比较复杂的,有兴趣可以查看官网了解,或者从下图中窥见一二:
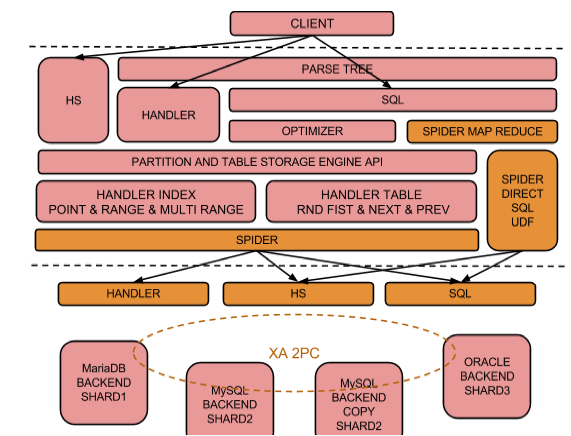
图源官网(https://mariadb.com/kb/en/spider-storage-engine-core-concepts/)