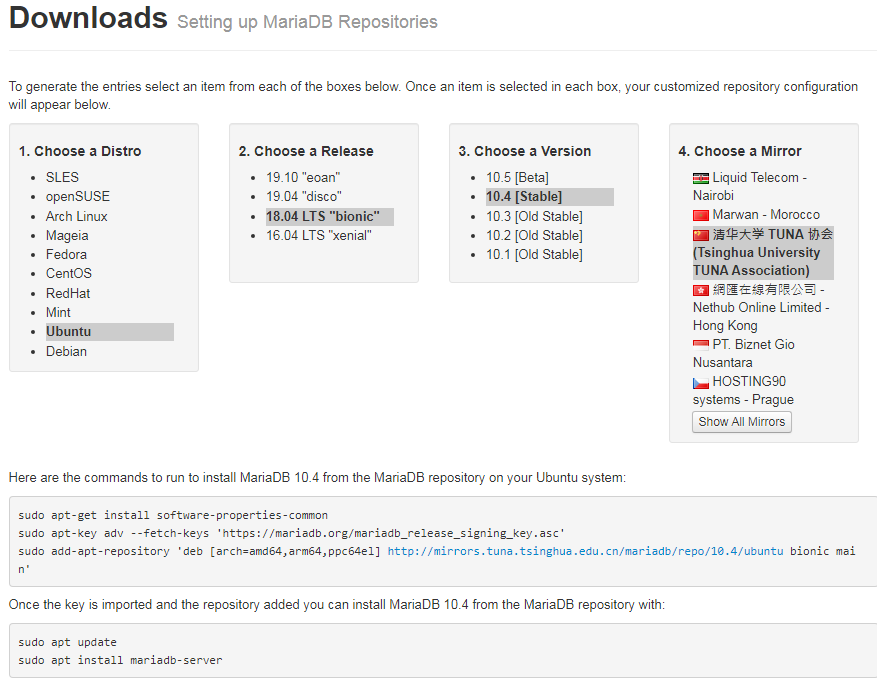
数据量不大的中小型规模 size 的 Table 原则是还是采用 Table+Index 设计为最佳化的思考重点。
在大数据考虑数据分片的时候,有两点也是重点:
一是空间,数据存放的存储空间是否足够,易于扩展。
二是时间,对于数据存取是否有限制,能否优化。
此外就是:
- 基本的数据与索引区隔无法满足 Big Data 所需的数据分片
- 高达数百 TB 的数据表毫无疑问将导致 DML 语法执行缺乏效率
- 海量型数据建议采用 分区(Partition) 机制分离储存数据
- 数据分区存放可以有效提升数据查询与异动操作
对于 MyISAM 引擎,可以设计分离数据文件和索引文件来加快数据存取。例如:
CREATE TABLE X (
…
)
ENGINE=MyISAM,
DATA DIRECTORY = '/var/p1',
INDEX DIRECTORY = '/var/p2';当然,InnoDB 采用 System TableSpace 集中存放,无法支持此种方式,需要通过设定去转换成一个 table 一个 file。
MariaDB 表分区(Table Partition)
MariaDB 10 提供 Table 分区储存功能,大量数据切割成不同储存区域(Partition),Partiton 底层的档案可再切成多档方式储存(Sub-Partition)。
使用 Plugin 方式扩充
由 Storage Engine 自行实作,MariaDB 已支持的包括 InnoDB, TokuDB , Memory, Aria, Spider、MyISAM, Archive, BLACKHOLE
MySQL 仅支援 InnoDB
MariaDB 透过内建的 Partiton Storage Engine 提供此项分区服务。
查看是否有安装此引擎:
SELECT * FROM information_schema.PLUGINS WHERE PLUGIN_NAME like "%part%";
系统管理方式与一般 tables 相同,System Partition 提供元数据(Metadata): Informaton_Schema.PARTITIONS。
分区作业时,有些东西还需要特别考虑,例如分区类型、分区计算、目标表的形态、分区前后的应用等等。
MariaDB 的分区类型使用示例
MariaDB 的分区类型主要有:
- RANGE ( 单一字段)
- LIST ( 单一字段)
- RANGE COLUMNS and LIST COLUMNS, HASH COLUMNS(多栏)
- HASH ( 单一字段)
- KEY ( 单一字段 )
- LINEAR HASH, LINEAR KEY
- SYSTEM_TIME
RANGE 分区类型
RANGE 分区类型用于为每个分区分配由分区表达式生成的值的范围。范围必须是有序的,连续的且不重叠的。最小值始终包含在第一个范围内。最高值可以包含在最后一个范围内,也可以不包含在最后一个范围内。
这种分区方法的一种变体 RANGE COLUMNS 允许我们使用多列和更多数据类型。
语法:
CREATE TABLE 语句的最后一部分可以是新表分区的定义。对于 RANGE 分区
PARTITION BY RANGE (partitioning_expression)
(
PARTITION partition_name VALUES LESS THAN (value),
[ PARTITION partition_name VALUES LESS THAN (value), ... ]
)说明:
- partitioning_expression 是一个 SQL 表达式,从每行返回一个值,最简单的就是一个字段名(column name),用于确定哪个分区需要包含一行数据( which partition should contain a row)。
- partition_name 是分区的名称。
- value 指示该分区的上限,表达式必须回传 deterministic / nonconstant 值(Integer 或 NULL)
- 不支持 stored functions 以及 user-defined functions
- 不支持 / 除法运算子( DIV , MOD 可 ) ( / 回传的是 Float 10/3 = 3.3 )
- 表达式不可消耗过多资源/时间
- 使用针对 Partition 最佳化过的分区函数(partitioning function),例如 YEAR() , TO_DAYS(), TO_SECONDS() 。
- 如果存在问题,可以将 MAXVALUE 指定为最后一个分区的值。但是请注意,不能拆分现有 RANGE 分区表的分区。可以附加新的分区,但是如果最后一个分区的上限为 MAXVALUE,则将无法添加新分区。
示例:
通过年份对日志表进行分区
CREATE TABLE test200221.log
(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
timestamp DATETIME NOT NULL,
user INT UNSIGNED,
ip BINARY(16),
action VARCHAR(20),
PRIMARY KEY (id,timestamp)
)
ENGINE = InnoDB
PARTITION BY RANGE (YEAR(timestamp))
(
PARTITION p0 VALUES LESS THAN (2013),
PARTITION p1 VALUES LESS THAN (2014),
PARTITION p2 VALUES LESS THAN (2015),
PARTITION p3 VALUES LESS THAN (2016)
);注意:
- 1、partitioning_expression 表达式中所引用的字段必须是 Primary key 中的成员
- 2、Primary key 包含了表达式中所有字段的组合,限缩 Unique keys 的使用
如果 partitioning_expression 表达式引用的字段不是,就会出现以下错误:
SQL 错误 [1503] [HY000]: (conn=51) A PRIMARY KEY must include all columns in the table's partitioning function- 3、一般情况下,不支持的分区字段类型有 TEXT,LongText,BLOB,CLOB …(前面有提到,返回值需要是 Integer 或 NULL)
- 4、此外,在使用分区函数(partitioning function)时,要注意函数和字段的正确性,否则可能会出现类似的问题:
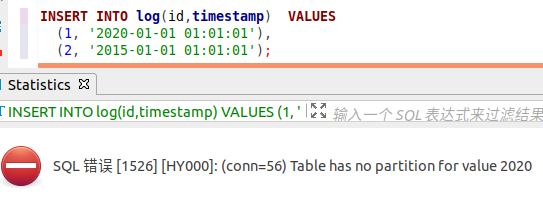
SQL 错误 [1486] [HY000]: (conn=51) Constant, random or timezone-dependent expressions in (sub)partitioning function are not allowed- 5、注意插入的数据是否有对应的分区。例如示例中分区有 4 个,对应 2013~2016 年的日志,如果此时插入的有是 2020 年的日志,没有该分区,可能出现类似的错误:
但可以添加 IGNORE 关键词去去除不符合的值。上述就会插入 2015 年的那条: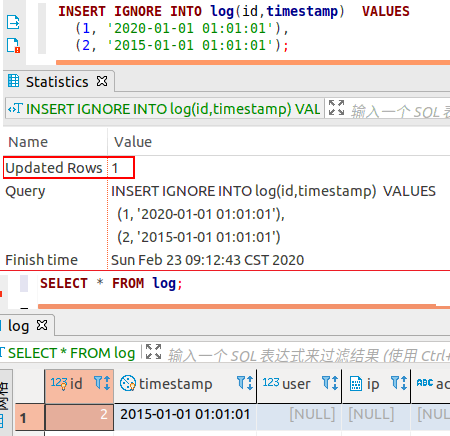
- 6、部分 Partition 语法 需要对 Partition 进行命名,MariaDB 可自行命名( pN , N(0~N ) ),人工编码最长长度 61 字符,推荐有意义的命名。
LIST 分区类型
LIST 分区在概念上类似于 RANGE 分区。在这两种情况下,都需要确定一个分区表达式(一个字段(column),或者稍微复杂一些的计算),然后使用它来确定哪些分区将包含每一行。但是,对于 RANGE 类型,分区是通过为每个分区分配一个值范围来完成的。对于 LIST 类型,将会为每个分区分配一组值。如果分区表达式可以返回一组有限的值(a limited set of values),则通常是首选方法。
这种分区方法的一种变体 LIST COLUMNS 允许使用多列和更多数据类型。
语法:
PARTITION BY LIST (partitioning_expression)
(
PARTITION partition_name VALUES IN (value_list),
[ PARTITION partition_name VALUES IN (value_list), ... ]
[ PARTITION partition_name DEFAULT ]
)说明:
- 依据数据类型,符合指定项目则存入指定 Partition
- partitioning_expression 是一个 SQL 表达式,从每行返回一个值,最简单的就是一个字段名(column name),用于确定哪个分区需要包含一行数据( which partition should contain a row)。
- partition_name 是分区的名称。
- value 是一系列值(a list of values),表达式返回这些值,就能存入该分区
- EXPRESSION 表达式 必须是 Integer 回传值
- 搭配 DEFAULT 收纳所有不符合其它分区条件的数据( 10.2 之后 加入),但也只能有一个 DEFUILT 分区。可设定超出范围的处理: NULL
示例:
依据文章语言分类,所有可能的筛选值必须判断,Language 事实上是 Foreign key 对应到 Language Table(所以用 id 表示),Partition table 不支持 Fkey,Language 必须是 正整数或 null。
DROP table if exists test200221.article;
CREATE TABLE test200221.article(
id integer unsigned not null auto_increment,
date date not null,
author varchar(100),
language tinyint unsigned,
text text,
primary key(id,language)
)ENGINE=InnoDB
partition by LIST (language)(
PARTITION p0 VALUES IN (1),
PARTITION p1 VALUES IN (2,3),
PARTITION p2 VALUES IN (4,5,6,7,8,9),
PARTITION px VALUES IN (NULL ) -- 或 PARTITION px DEFAULT
)RANGE COLUMNS 和 LIST COLUMNS 分区类型
RANGE COLUMNS 和 LIST COLUMNS 分别是 RANGE 和 LIST 的变体。对于这些分区类型,不是一个分区表达式(partitioning _expression)。而是接受一个或多个字段(columns)。适用以下规则:
- 该列表可以包含一个或多个字段(columns)。
- 字段(columns)可以是任何 integer,string,DATE 和 DATETIME 类型。
- 仅允许使用纯字段(bare columns),不能加表达式。
将所有指定的列与指定的值进行比较,以确定哪个分区应包含特定的行。
字段型别:
Integer ( 不可产生负数 )、Date, DateTime、CHAR, VARCHAR, BINARY , VARBINARY、不可使用任何 functions, 运算子符号 (只能单纯使用字段…)
语法:
RANGE COLUMNS 分区类型:
PARTITION BY RANGE COLUMNS (col1, col2, ...)
(
PARTITION partition_name VALUES LESS THAN (value1, value2, ...),
[ PARTITION partition_name VALUES LESS THAN (value1, value2, ...), ... ]
)LIST COLUMNS 分区类型:
PARTITION BY LIST COLUMNS (partitioning_expression)
(
PARTITION partition_name VALUES IN (value1, value2, ...),
[ PARTITION partition_name VALUES IN (value1, value2, ...), ... ]
[ PARTITION partititon_name DEFAULT ]
)两者的区别:
RANGE COLUMNS 是返回的值小于指定的值,第一个匹配条件的分区将包含该值;
LIST COLUMNS 返回的值包含在给定的值里面,同样允许且仅运行一个 DEFAULT 分区。
示例,修改上述 article 表,新加 year 字段:
DROP table if exists test200221.article2;
CREATE TABLE test200221.article2 (
id INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,
date DATE NOT NULL,
year CHAR(4) NOT NULL,
author VARCHAR(100),
language TINYINT UNSIGNED,
text TEXT,
PRIMARY KEY (id, language, year)
)
ENGINE = InnoDB
PARTITION BY RANGE COLUMNS (language, year) (
PARTITION p0 VALUES LESS THAN (1, '2010'),
PARTITION p1 VALUES LESS THAN (1, '2020'),
PARTITION p2 VALUES LESS THAN (100, '2010'),
PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE)
);MariaDB 的分区的限制(Partitioning Limitations)
每个表最多可包含 8192 个分区(自 MariaDB 10.0.4)。在 MariaDB 5.5 和 10.0.3 中,限制是 1024。
目前,查询永远不会并行化,即使它们涉及多个分区。
只有当存储引擎支持分区时,才能对表进行分区。
所有分区必须使用相同的存储引擎。
分区表不能包含外键,也不能被外键引用。
查询缓存(query cache)不知道分区和分区修剪(partitioning and partition pruning)。修改分区将使与整个表相关的条目失效。
当 binlog_format=ROW 且分区表被更新(update)时,更新的速度可能比等效的非分区表更慢。
分区表的分区表达式中使用的所有字段(column)必须是必须是 unique 结果( PRIMARY, UNIQUE_KEY 可支持)。
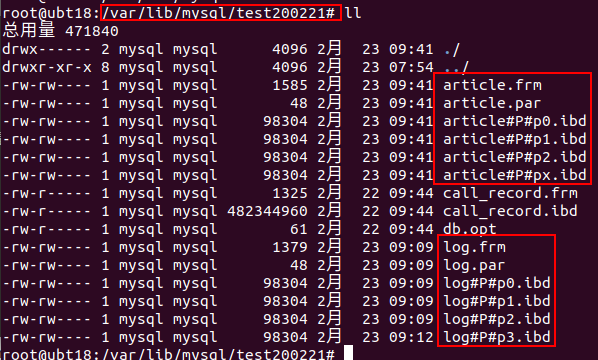
分区文件
分割后的 Table 将产生多个个别档案
文件名编码: table_name#P#partition_name.ext
在 InnoDB 下,会有以下 3 类:
- table_name.frm
- table_name.par
- table_name#P#partition_name.ibd
分区修剪(Partition Pruning)和分区选择(partition selection)
当 WHERE 子句与分区表达式有关联时,优化器知道哪些分区与查询相关。其它分区将不会被读取。这种优化称为分区修剪。
可以使用 EXPLAIN 分区来了解将为给定的查询读取哪些分区。名为 partitions 的列将包含以逗号分隔的被访问分区列表。
以之前的 article 表为例,回顾一下创建语言:
CREATE TABLE test200221.article(
id integer unsigned not null auto_increment,
publish_date date not null,
author varchar(100),
language tinyint unsigned,
text text,
primary key(id,language)
)ENGINE=InnoDB
partition by LIST (language)(
PARTITION p0 VALUES IN (1),
PARTITION p1 VALUES IN (2,3),
PARTITION p2 VALUES IN (4,5,6,7,8,9),
PARTITION px VALUES IN (NULL ) -- PARTITION px DEFAULT
)使用EXPLAIN PARTITIONS来查看哪些分区会被使用到:
EXPLAIN PARTITIONS SELECT * FROM article WHERE language < 4;
从结果来看,的确在WHERE language < 4;的条件下,只有 p0 和 p1 分区会有访问到。
如果优化器不知道或无法推断出哪些分区会被使用到,可以通过 PARTITION 子句强制 MariaDB 仅访问给定分区(MariaDB 10.0 开始),这也被称为分区选择。
例如:
SELECT * FROM article PARTITION (p2) WHERE language = 5;所有 DML 语句均支持 PARTITION 子句:SELECT、INSERT、UPDATE、DELETE、REPLACE、LOAD DATA 等。
通常情况下,分区修剪会用在触发器(triggers)语句中。
但是如果在表上定义了 BEFORE INSERT 或者 BEFORE UPDATE 的触发器,则 MariaDB 不会预先知道分区表达式中使用的字段(column)是否会更改。因此,被迫锁定所有分区。